Random Forest is a flexible and easy-to-use machine learning algorithm that, even without hyperparameter tuning, yields good results in most cases. It is also one of the most commonly used algorithms because it is simple and can be used for both classification and regression tasks. In this article, you will learn how the random forest algorithm works and how it works.
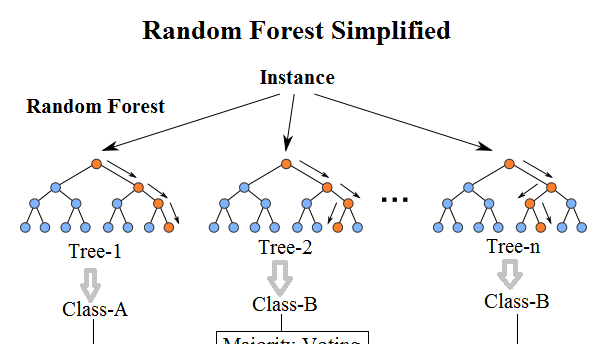
Random forest is a supervised learning algorithm. Just like the name you see, it creates a forest and gives it some sort of randomness. The “forest†built is the integration of decision trees, and most of the time it is trained using the “bagging†method. The bagging method, bootstrap aggregating, uses randomly selected training data and then constructs the classifier. Finally, the learned model is combined to increase the overall effect.
In short: Random forests have built multiple decision trees and combined them to get more accurate and stable predictions. One of the great advantages of a random forest is that it can be used for both classification and regression problems, which form exactly what most current machine learning systems need to face. Next, we will explore how random forests can be used for classification problems, because classification is sometimes considered the cornerstone of machine learning. Below, you can see what the random forest of two trees looks like:
With a few exceptions, the random forest classifier uses all of the decision tree classifiers and the hyperparameters of the bagging classifier to control the overall structure. Instead of building a bagging classifier and passing it to the decision tree classifier, you can use the random forest classifier class directly, which is more convenient and optimized for the decision tree. It should be noted that the regression problem also has a random forest regression device corresponding to it.
The growth of trees in random forest algorithms introduces additional randomness to the model. Different from the decision tree, each node is segmented into the best features to minimize the error. In the random forest, we select the randomly selected features to construct the optimal segmentation. Therefore, when you are in a random forest, considering only the random subset used to segment the nodes, you can even make the tree more random by using random thresholds on each feature instead of searching for the optimal threshold as a normal decision tree. This process produces a wide range of versatility and usually results in better models.
An example of an algorithm that is easier to understand
Imagine a man named Andrew who wants to know where he should go during a holiday trip. He will consult with friends who know him.
At first, he went looking for a friend who would ask Andrew where he had been. He liked or didn't like these places. Based on these answers, Andrew can give some advice. This is a typical decision tree algorithm.
Through Andrew's answer, the friend developed some rules to guide the places that should be recommended. Later, Andrew began to seek advice from more and more friends, they would ask him different questions and give some suggestions. Finally, Andrew chose the most recommended place, which is the typical random forest algorithm.
The Importance of the Characteristics of Random Forest Algorithms for Machine Learning Algorithms
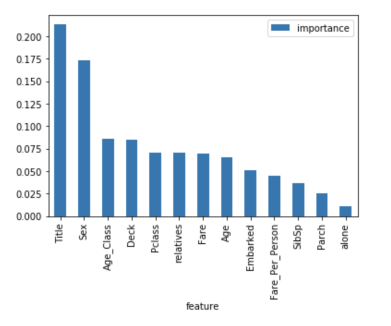
Another advantage of the random forest algorithm is that the relative importance of each feature to the prediction can be easily measured. Sklearn provides a good tool for this, which measures the importance of features by looking at how much the use of this feature reduces the inhomogeneity of all trees in the forest. It automatically calculates the score for each feature after training and normalizes the results so that the sum of the importance of all features equals one.
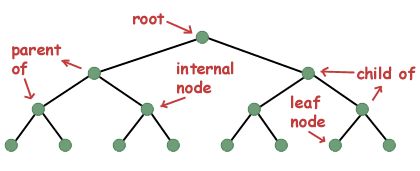
If you don't know how the decision tree works and don't know what a leaf or node is, you can refer to the Wikipedia description: In the decision tree, each internal node represents a "test" of a class of attributes (for example, a coin flip) The result is positive or negative), each branch represents the result of the test, and each leaf node represents a class label (a decision made after all attributes have been calculated). A leaf is a node that has no next branch.
By looking at the importance of features, you can know which features don't contribute enough or don't contribute to the forecasting process, and decide whether to discard them. This is important because, in general, the more features a machine learns have, the more likely the model is to overfit and vice versa.
Below you can see a table and a visual chart showing the importance of the 13 features. I used the famous Titanic dataset on kaggle in the supervised classification project.
The difference between decision trees and random forests
As I mentioned earlier, random forests are a collection of decision trees, but there are still some differences.
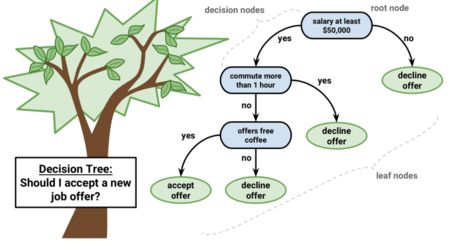
If you enter a training dataset with features and labels into the decision tree, it will develop some rule sets for prediction.
For example, if you want to predict whether someone will click on an online ad, you can collect past clickers for that ad and the characteristics that describe their decision. Once you put these features and tags into the decision tree, it generates nodes and rules, and then you can predict whether the ads will be clicked. But the decision tree usually generates nodes and rules by calculating the information gain and the Gini index. In contrast, random forests are random.
Another difference is that "deep" decision trees tend to suffer from fitting problems. Random forests can prevent over-fitting in most cases by creating random subsets of features and using them to build smaller trees and then subtrees. It should be noted that this also makes the calculation slower and depends on the number of trees built by the random forest.
Important hyperparameters of random forest algorithm for machine learning algorithmsParameters in random forests are either used to enhance the predictive power of the model or to make the model faster. The hyperparameters in the random forest function built into sklearns are discussed below.

Improve model prediction accuracy
First, the "n_estimators" hyperparameter indicates the number of trees the algorithm established before making the maximum vote or taking the predicted average. In general, the more the number of trees, the better the performance and the more stable the prediction, but it will also slow down the calculation.
Another important hyperparameter is "max_features", which represents the maximum number of features a random forest can have in a single tree. Sklearn provides several options, which are described in their documentation:
http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
The last important hyperparameter is "min_sample_leaf", which, as its name suggests, determines the number of leaves.
Speed ​​up model calculation
The "n_jobs" hyperparameter indicates the number of processors allowed by the engine. If the value is 1, only one processor can be used. A value of -1 means there is no limit.
"random_state" indicates a random number seed to ensure that the output of the model is reproducible. When it is assigned a specified value and the model training has the same parameters and the same training data, the model will always produce the same result.
Finally, there is an "oob_score" (also known as oob sampling), which is a random forest cross-validation method. In this sample, approximately one-third of the data is not used for model training, but is used to evaluate the performance of the model. These samples are referred to as out-of-bag samples. It is very similar to the leave-one-out cross-validation method, but with little additional computational burden.
Advantages and disadvantages analysis
As I mentioned before, one of the advantages of a random forest is that it can be used for regression and classification tasks, and it is easy to see the relative importance of the input characteristics of the model.
Random forests are also considered to be a very convenient and easy to use algorithm, as it is the default hyperparameter that usually produces a good prediction. The number of hyperparameters is not so much, and the meaning they represent is intuitive and easy to understand.
A major problem in machine learning is overfitting, but in most cases this is not as easy for random forest classifiers. Because as long as there are enough trees in the forest, the classifier will not overfit the model.
The main limitation of random forests is that using a large number of trees can make the algorithm slow and impossible to predict in real time. In general, these algorithms are very fast and the predictions are very slow. The more accurate the prediction, the more trees you need, which will result in a slower model. In most real-world applications, the random forest algorithm is fast enough, but it will certainly encounter high-time requirements, and only other methods are preferred.
Of course, random forests are a predictive modeling tool, not a descriptive tool. That is, if you are looking for a description of the relationship in the data, then other methods are preferred.
Scope of application
The random forest algorithm can be used in many different fields such as banking, stock markets, medicine and e-commerce. In the banking sector, it is often used to detect customers who use banking services at a higher frequency than ordinary people and pay their debts in a timely manner. At the same time, it will also be used to detect customers who want to scam banks. In the financial sector, it can be used to predict trends in future stocks. In the healthcare field, it can be used to identify the correct combination of pharmaceutical ingredients and to analyze the patient's medical history to identify the disease. In addition, in the field of e-commerce, random forests can be used to determine if a customer really likes a product.
to sum up
Random forests are a good algorithm for training early in the model development process, understanding how it works, and because of its simplicity, it is difficult to construct a "bad" random forest. If you need to develop a model in a short time, Random Forest will be a good choice. Most importantly, it provides a good representation of the importance of the features you choose.
Random forests are also hard to beat in terms of performance. Of course, no better than better, you can always find a better performance model, such as neural networks, but such models usually take more time to develop. Most importantly, random forests can handle feature types of many different attributes at the same time, such as binary, category, and numeric. In general, random forests are a (relatively large) fast, simple, and flexible tool, although they have certain limitations.
Withstand high voltage up to 750V (IEC/EN standard)
UL 94V-2 or UL 94V-0 flame retardant housing
Anti-falling screws
Optional wire protection
1~12 poles, dividable as requested
Maximum wiring capacity of 25 mm2
25 mm2 connector blocks, 60 amp Terminal Blocks,traditional screw type terminal blocks,Pa66 Terminal Blocks
Jiangmen Krealux Electrical Appliances Co.,Ltd. , https://www.krealux-online.com