Compared to GPUs and GPPs, FPGAs offer an attractive alternative to meeting the hardware requirements for deep learning. With pipelined parallel computing capabilities and efficient power consumption, FPGAs will demonstrate the unique advantages that GPUs and GPPs do not have in general deep learning applications. At the same time, algorithm design tools are maturing, and it is now possible to integrate FPGAs into commonly used deep learning frameworks. In the future, FPGAs will effectively adapt to the development trend of deep learning, and ensure that related applications and research can be realized freely.
Author: Griffin Lacey Graham Taylor Shawaki Areibi Source: arxiv
Abstract <br> The rapid growth of data volume and accessibility in recent years has transformed the artificial intelligence algorithm design philosophy. The manual creation of algorithms has been replaced by the ability of computers to automatically acquire combinable systems from large amounts of data, leading to major breakthroughs in key areas such as computer vision, speech recognition, and natural language processing. Deep learning is the most commonly used technology in these fields, and it has also received much attention from the industry. However, deep learning models require an extremely large amount of data and computing power, and only better hardware acceleration conditions can meet the needs of existing data and model scales. Existing solutions use a graphics processing unit (GPU) cluster as a general purpose computing graphics processing unit (GPGPU), but field programmable gate arrays (FPGAs) offer another solution worth exploring. Increasingly popular FPGA design tools make it more compatible with the upper-layer software often used in deep learning, making FPGAs easier for model builders and deployers. The flexible FPGA architecture allows researchers to explore model optimization outside of a fixed architecture such as a GPU. At the same time, FPGAs perform better under unit power consumption, which is critical for large-scale server deployments or research on embedded applications with limited resources. This article examines deep learning and FPGAs from a hardware acceleration perspective, pointing out the trends and innovations that make these technologies match each other and motivating how FPGAs can help deepen the development of deep learning.

1. Introduction <br> Machine learning has a profound impact on daily life. Whether it's clicking on personalized recommendations on the site, using voice communication on a smartphone, or using face recognition technology to take photos, some form of artificial intelligence is used. This new trend of artificial intelligence is also accompanied by a change in the concept of algorithm design. In the past, data-based machine learning mostly used the expertise of specific fields to artificially “shape†the “features†to be learned. The ability of computers to acquire combined feature extraction systems from a large amount of sample data makes computer vision, speech recognition and Significant performance breakthroughs have been achieved in key areas such as natural language processing. Research on these data-driven technologies, known as deep learning, is now being watched by two important groups in the technology world: one is the researchers who want to use and train these models to achieve extremely high-performance cross-task computing, and the second is hope New applications in the real world to apply these models to application scientists. However, they all face a constraint that the hardware acceleration capability still needs to be strengthened to meet the need to expand the size of existing data and algorithms.
For deep learning, current hardware acceleration relies primarily on the use of graphics processing unit (GPU) clusters as general purpose computing graphics processing units (GPGPUs). Compared to traditional general-purpose processors (GPPs), the core computing power of GPUs is several orders of magnitude more, and it is easier to perform parallel computing. In particular, NVIDIA CUDA, as the most mainstream GPGPU writing platform, is used by all major deep learning tools for GPU acceleration. Recently, the open parallel programming standard OpenCL has received much attention as an alternative tool for heterogeneous hardware programming, and the enthusiasm for these tools is also rising. Although OpenCL has received slightly less support than CUDA in the field of deep learning, OpenCL has two unique features. First, OpenCL is open source and free to developers, unlike the CUDA single vendor approach. Second, OpenCL supports a range of hardware, including GPUs, GPP, Field Programmable Gate Arrays (FPGAs), and Digital Signal Processors (DSPs).
1.1. FPGA
As a powerful GPU in terms of algorithm acceleration, it is especially important that FPGAs support different hardware immediately. The difference between FPGA and GPU is that the hardware configuration is flexible, and the FPGA can provide better performance than the GPU in unit energy consumption when running sub-programs in the deep learning (such as the calculation of sliding windows). However, setting up an FPGA requires specific hardware knowledge that many researchers and application scientists do not have. Because of this, FPGAs are often seen as an expert-specific architecture. Recently, FPGA tools have begun to adopt software-level programming models including OpenCL, making them increasingly popular with users trained by mainstream software development.
For researchers looking at a range of design tools, the screening criteria for tools are usually related to whether they have user-friendly software development tools, whether they have flexible and scalable model design methods, and whether they can be quickly calculated to reduce the training of large models. Time related. As FPGAs become easier to write because of the emergence of highly abstract design tools, their reconfigurability makes custom architectures possible, while high parallel computing power increases instruction execution speed, and FPGAs will be researchers for deep learning. brings advantages.
For application scientists, despite similar tool-level choices, the focus of hardware selection is to maximize performance per unit of energy consumption, thereby reducing costs for large-scale operations. As a result, FPGAs benefit from deep learning application scientists with the power of unit power consumption and the ability to customize the architecture for specific applications.
FPGAs can meet the needs of both types of audiences and are a logical choice. This article examines the current state of deep learning on FPGAs and the current technological developments used to bridge the gap between the two. Therefore, this article has three important purposes. First, it points out that there is an opportunity to explore a new hardware acceleration platform in the field of deep learning, and FPGA is an ideal choice. Second, outline the current state of FPGA support for deep learning and point out potential limitations. Finally, make key recommendations for the future direction of FPGA hardware acceleration to help solve the problems faced by deep learning in the future.
2. FPGA
Traditionally, the trade-off between flexibility and performance must be considered when evaluating the acceleration of a hardware platform. On the one hand, general purpose processors (GPPs) offer a high degree of flexibility and ease of use, but performance is relatively inefficient. These platforms are often more accessible, can be produced at a lower price, and are suitable for multiple uses and reuse. On the other hand, application specific integrated circuits (ASICs) provide high performance at the expense of being less flexible and more difficult to produce. These circuits are dedicated to a particular application and are expensive and time consuming to produce.
FPGAs are a compromise between these two extremes. FPGAs are a class of more general-purpose programmable logic devices (PLDs) and, in a nutshell, are reconfigurable integrated circuits. As a result, FPGAs offer both the performance benefits of integrated circuits and the flexibility of GPP reconfigurability. FPGAs can implement sequential logic simply by using flip-flops (FFs) and by using look-up tables (LUTs). Modern FPGAs also contain hardened components to implement common functions such as full processor cores, communication cores, computing cores, and block memory (BRAM). In addition, current FPGA trends tend to be system-on-chip (SoC) design methods, where ARM coprocessors and FPGAs are typically located on the same chip. The current FPGA market is dominated by Xilinx, which accounts for more than 85% of the market. In addition, FPGAs are rapidly replacing ASICs and Application Specific Standard Products (ASSPs) to implement fixed-function logic. The FPGA market is expected to reach $10 billion in 2016.
For deep learning, FPGAs offer significant potential over traditional GPP acceleration capabilities. The implementation of GPP at the software level relies on the traditional von Neumann architecture, where instructions and data are stored in external memory and fetched when needed. This drives the emergence of caches, greatly reducing expensive external memory operations. The bottleneck of this architecture is the communication between the processor and the memory, which seriously weakens the performance of GPP, especially the storage information technology that deep learning often needs to acquire. In comparison, FPGA programmable logic primitives can be used to implement data and control paths in common logic functions without relying on the von Neumann structure. They can also take advantage of distributed on-chip memory and deep pipeline parallelism, which naturally fits into the feedforward deep learning approach. Modern FPGAs also support partial dynamic reconfiguration, and another part can still be used when part of the FPGA is reconfigured. This will have an impact on the large-scale deep learning model, and the layers of the FPGA can be reconfigured without disturbing the ongoing calculations at other layers. This will be available for models that cannot be accommodated by a single FPGA, while also reducing the high cost of global storage reads by saving intermediate results in local storage.
Most importantly, FPGAs provide another perspective for the exploration of hardware-accelerated designs compared to GPUs. GPUs and other fixed architectures are designed to follow a software execution model and build parallel structures around the autonomic computing unit to perform tasks. Therefore, the goal of developing a GPU for deep learning technology is to adapt the algorithm to this model, let the calculations be done in parallel, and ensure that the data is interdependent. In contrast, the FPGA architecture is specifically tailored for the application. When developing deep learning techniques for FPGAs, less emphasis is placed on adapting the algorithm to a fixed computational structure, leaving more freedom to explore algorithm-level optimization. Techniques that require a lot of complex underlying hardware control operations are difficult to implement in the upper software language, but are particularly attractive for FPGA implementation. However, this flexibility comes at the cost of a large amount of compilation (positioning and looping) time, which is often a problem for researchers who need to iterate quickly through the design loop.
In addition to compile time, it is particularly difficult to attract researchers and application scientists who prefer upper-level programming languages ​​to develop FPGAs. Being fluent in a software language often means that you can easily learn another software language, but not for hardware language translation skills. The most common languages ​​for FPGAs are Verilog and VHDL, both of which are Hardware Description Languages ​​(HDL). The main difference between these languages ​​and traditional software languages ​​is that HDL simply describes the hardware, while software languages ​​such as C describe sequential instructions without having to know the implementation details at the hardware level. Efficiently describing hardware requires expertise in digital design and circuitry, although some of the underlying implementation decisions can be left to automated synthesis tools to achieve, but often fail to achieve efficient design. As a result, researchers and application scientists tend to choose software design because they are already very mature, with a large number of abstract and convenient classifications to improve programmer productivity. These trends have made the FPGA field now favoring highly abstract design tools.
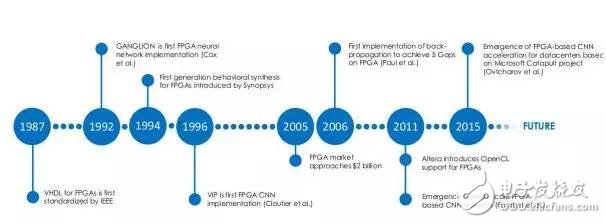 FPGA deep learning research milestones:
FPGA deep learning research milestones:
1987VHDL becomes IEEE standard
1992GANGLION became the first FPGA neural network hardware implementation project (Cox et al.)
1994 Synopsys introduces the first generation of FPGA behavior integration program
1996VIP became the first FPGA implementation of FPGA (ClouTIer et al.)
2005 FPGA market value is close to 2 billion US dollars
2006 First use BP algorithm to achieve 5 GOPS processing capability on FPGA
2011 Altera introduces OpenCL and supports FPGA
Large-scale FPGA-based CNN algorithm research (Farabet et al.)
2016 based on the Microsoft Catapult project, the emergence of FPGA-based data center CNN algorithm acceleration (Ovtcharov et al.)
4. Future Prospects <br> The future of deep learning, whether in terms of FPGA or overall, depends primarily on scalability. For these technologies to successfully solve future problems, they must be extended to support the rapid growth of data scale and architecture. FPGA technology is adapting to this trend, and hardware is moving toward larger memory, smaller feature points, and better interconnectivity to accommodate multiple FPGA configurations. Intel's acquisition of Altera, IBM and Xilinx, both indicate changes in the FPGA field, and may soon see the integration of FPGAs with personal applications and data center applications. In addition, algorithm design tools may move toward further abstraction and experiencing software, attracting a wider range of users.
4.1. Common Deep Learning Software Tools <br> Among the most commonly used software tools for deep learning, some tools have already recognized the need to support OpenCL while supporting CUDA. This will make it easier for FPGAs to achieve deep learning. Although as far as we know, there are currently no deep learning tools that explicitly support FPGAs, but the following table lists which tools are moving toward supporting OpenCL:
Caffe, developed by the Berkeley Center for Visual and Learning, provides informal support for OpenCL in its GreenTea project. Caffe also supports AMD versions of OpenCL.
Torch, a scientific computing framework based on the Lua language, has a wide range of uses, and its project CLTorch provides informal support for OpenCL.
Theano, developed by the University of Montreal, is currently providing gpuarray backends to provide informal support for OpenCL.
DeepCL, an OpenCL library developed by Hugh Perkins, is used to train convolutional neural networks.
For those who have just entered the field and want to choose tools, our advice is to start with Caffe, because it is very common, support is good, and the user interface is simple. It is also easy to experiment with pre-trained models using Caffe's model zoo library.
4.2. Adding Training Freedoms <br> Some people may think that the process of training machine learning algorithms is completely automatic. In fact, some hyperparameters need to be adjusted. This is especially true for deep learning, where the complexity of the model is often accompanied by a large number of possible hyperparameter combinations. The hyperparameters that can be adjusted include the number of training iterations, the learning rate, the batch gradient size, the number of hidden cells, and the number of layers. Adjusting these parameters is equivalent to picking the model that best fits a problem among all possible models. In the traditional approach, the setting of hyperparameters is either empirical or based on a systematic grid search or a more efficient random search. Recently, researchers have turned to adaptive methods, and the results of the hyperparameter adjustment are the basis for configuration. Among them, Bayesian optimization is the most commonly used method.
Regardless of the method used to adjust the hyperparameters, the current training process using fixed architectures limits the possibilities of the model to some extent, that is, we may only look at a part of all the solutions. Fixed architecture makes it easy to explore hyperparameter settings within a model (eg, hidden cell count, number of layers, etc.), but it is difficult to explore parameter settings between different models (eg, different model categories) because It can take a long time to train on a model that does not simply fit a fixed architecture. Conversely, the FPGA's flexible architecture may be better suited to the above optimization types because FPGAs can write a completely different hardware architecture and accelerate at runtime.
4.3. Low power compute clusters Low-energy computing node clusters <br> The most fascinating aspect of the deep learning model is its ability to scale. Whether it's to find complex high-level features from data or to improve performance for data center applications, deep learning techniques often scale across multi-node computing infrastructure. The current solution uses GPU clusters and MPIs with Infiniband interconnect technology to enable parallel computing power and fast data transfer between nodes. However, when the load of large-scale applications is getting different, using FPGAs may be a better method. The FPGA's programmable circuitry allows the system to be reconfigured based on application and load, while the FPGA's power consumption ratio is high, helping next-generation data centers reduce costs.
Author: Griffin Lacey Graham Taylor Shawaki Areibi Source: arxiv
Abstract <br> The rapid growth of data volume and accessibility in recent years has transformed the artificial intelligence algorithm design philosophy. The manual creation of algorithms has been replaced by the ability of computers to automatically acquire combinable systems from large amounts of data, leading to major breakthroughs in key areas such as computer vision, speech recognition, and natural language processing. Deep learning is the most commonly used technology in these fields, and it has also received much attention from the industry. However, deep learning models require an extremely large amount of data and computing power, and only better hardware acceleration conditions can meet the needs of existing data and model scales. Existing solutions use a graphics processing unit (GPU) cluster as a general purpose computing graphics processing unit (GPGPU), but field programmable gate arrays (FPGAs) offer another solution worth exploring. Increasingly popular FPGA design tools make it more compatible with the upper-layer software often used in deep learning, making FPGAs easier for model builders and deployers. The flexible FPGA architecture allows researchers to explore model optimization outside of a fixed architecture such as a GPU. At the same time, FPGAs perform better under unit power consumption, which is critical for large-scale server deployments or research on embedded applications with limited resources. This article examines deep learning and FPGAs from a hardware acceleration perspective, pointing out the trends and innovations that make these technologies match each other and motivating how FPGAs can help deepen the development of deep learning.
1. Introduction <br> Machine learning has a profound impact on daily life. Whether it's clicking on personalized recommendations on the site, using voice communication on a smartphone, or using face recognition technology to take photos, some form of artificial intelligence is used. This new trend of artificial intelligence is also accompanied by a change in the concept of algorithm design. In the past, data-based machine learning mostly used the expertise of specific fields to artificially “shape†the “features†to be learned. The ability of computers to acquire combined feature extraction systems from a large amount of sample data makes computer vision, speech recognition and Significant performance breakthroughs have been achieved in key areas such as natural language processing. Research on these data-driven technologies, known as deep learning, is now being watched by two important groups in the technology world: one is the researchers who want to use and train these models to achieve extremely high-performance cross-task computing, and the second is hope New applications in the real world to apply these models to application scientists. However, they all face a constraint that the hardware acceleration capability still needs to be strengthened to meet the need to expand the size of existing data and algorithms.
For deep learning, current hardware acceleration relies primarily on the use of graphics processing unit (GPU) clusters as general purpose computing graphics processing units (GPGPUs). Compared to traditional general-purpose processors (GPPs), the core computing power of GPUs is several orders of magnitude more, and it is easier to perform parallel computing. In particular, NVIDIA CUDA, as the most mainstream GPGPU writing platform, is used by all major deep learning tools for GPU acceleration. Recently, the open parallel programming standard OpenCL has received much attention as an alternative tool for heterogeneous hardware programming, and the enthusiasm for these tools is also rising. Although OpenCL has received slightly less support than CUDA in the field of deep learning, OpenCL has two unique features. First, OpenCL is open source and free to developers, unlike the CUDA single vendor approach. Second, OpenCL supports a range of hardware, including GPUs, GPP, Field Programmable Gate Arrays (FPGAs), and Digital Signal Processors (DSPs).
1.1. FPGA
As a powerful GPU in terms of algorithm acceleration, it is especially important that FPGAs support different hardware immediately. The difference between FPGA and GPU is that the hardware configuration is flexible, and the FPGA can provide better performance than the GPU in unit energy consumption when running sub-programs in the deep learning (such as the calculation of sliding windows). However, setting up an FPGA requires specific hardware knowledge that many researchers and application scientists do not have. Because of this, FPGAs are often seen as an expert-specific architecture. Recently, FPGA tools have begun to adopt software-level programming models including OpenCL, making them increasingly popular with users trained by mainstream software development.
For researchers looking at a range of design tools, the screening criteria for tools are usually related to whether they have user-friendly software development tools, whether they have flexible and scalable model design methods, and whether they can be quickly calculated to reduce the training of large models. Time related. As FPGAs become easier to write because of the emergence of highly abstract design tools, their reconfigurability makes custom architectures possible, while high parallel computing power increases instruction execution speed, and FPGAs will be researchers for deep learning. brings advantages.
For application scientists, despite similar tool-level choices, the focus of hardware selection is to maximize performance per unit of energy consumption, thereby reducing costs for large-scale operations. As a result, FPGAs benefit from deep learning application scientists with the power of unit power consumption and the ability to customize the architecture for specific applications.
FPGAs can meet the needs of both types of audiences and are a logical choice. This article examines the current state of deep learning on FPGAs and the current technological developments used to bridge the gap between the two. Therefore, this article has three important purposes. First, it points out that there is an opportunity to explore a new hardware acceleration platform in the field of deep learning, and FPGA is an ideal choice. Second, outline the current state of FPGA support for deep learning and point out potential limitations. Finally, make key recommendations for the future direction of FPGA hardware acceleration to help solve the problems faced by deep learning in the future.
2. FPGA
Traditionally, the trade-off between flexibility and performance must be considered when evaluating the acceleration of a hardware platform. On the one hand, general purpose processors (GPPs) offer a high degree of flexibility and ease of use, but performance is relatively inefficient. These platforms are often more accessible, can be produced at a lower price, and are suitable for multiple uses and reuse. On the other hand, application specific integrated circuits (ASICs) provide high performance at the expense of being less flexible and more difficult to produce. These circuits are dedicated to a particular application and are expensive and time consuming to produce.
FPGAs are a compromise between these two extremes. FPGAs are a class of more general-purpose programmable logic devices (PLDs) and, in a nutshell, are reconfigurable integrated circuits. As a result, FPGAs offer both the performance benefits of integrated circuits and the flexibility of GPP reconfigurability. FPGAs can implement sequential logic simply by using flip-flops (FFs) and by using look-up tables (LUTs). Modern FPGAs also contain hardened components to implement common functions such as full processor cores, communication cores, computing cores, and block memory (BRAM). In addition, current FPGA trends tend to be system-on-chip (SoC) design methods, where ARM coprocessors and FPGAs are typically located on the same chip. The current FPGA market is dominated by Xilinx, which accounts for more than 85% of the market. In addition, FPGAs are rapidly replacing ASICs and Application Specific Standard Products (ASSPs) to implement fixed-function logic. The FPGA market is expected to reach $10 billion in 2016.
For deep learning, FPGAs offer significant potential over traditional GPP acceleration capabilities. The implementation of GPP at the software level relies on the traditional von Neumann architecture, where instructions and data are stored in external memory and fetched when needed. This drives the emergence of caches, greatly reducing expensive external memory operations. The bottleneck of this architecture is the communication between the processor and the memory, which seriously weakens the performance of GPP, especially the storage information technology that deep learning often needs to acquire. In comparison, FPGA programmable logic primitives can be used to implement data and control paths in common logic functions without relying on the von Neumann structure. They can also take advantage of distributed on-chip memory and deep pipeline parallelism, which naturally fits into the feedforward deep learning approach. Modern FPGAs also support partial dynamic reconfiguration, and another part can still be used when part of the FPGA is reconfigured. This will have an impact on the large-scale deep learning model, and the layers of the FPGA can be reconfigured without disturbing the ongoing calculations at other layers. This will be available for models that cannot be accommodated by a single FPGA, while also reducing the high cost of global storage reads by saving intermediate results in local storage.
Most importantly, FPGAs provide another perspective for the exploration of hardware-accelerated designs compared to GPUs. GPUs and other fixed architectures are designed to follow a software execution model and build parallel structures around the autonomic computing unit to perform tasks. Therefore, the goal of developing a GPU for deep learning technology is to adapt the algorithm to this model, let the calculations be done in parallel, and ensure that the data is interdependent. In contrast, the FPGA architecture is specifically tailored for the application. When developing deep learning techniques for FPGAs, less emphasis is placed on adapting the algorithm to a fixed computational structure, leaving more freedom to explore algorithm-level optimization. Techniques that require a lot of complex underlying hardware control operations are difficult to implement in the upper software language, but are particularly attractive for FPGA implementation. However, this flexibility comes at the cost of a large amount of compilation (positioning and looping) time, which is often a problem for researchers who need to iterate quickly through the design loop.
In addition to compile time, it is particularly difficult to attract researchers and application scientists who prefer upper-level programming languages ​​to develop FPGAs. Being fluent in a software language often means that you can easily learn another software language, but not for hardware language translation skills. The most common languages ​​for FPGAs are Verilog and VHDL, both of which are Hardware Description Languages ​​(HDL). The main difference between these languages ​​and traditional software languages ​​is that HDL simply describes the hardware, while software languages ​​such as C describe sequential instructions without having to know the implementation details at the hardware level. Efficiently describing hardware requires expertise in digital design and circuitry, although some of the underlying implementation decisions can be left to automated synthesis tools to achieve, but often fail to achieve efficient design. As a result, researchers and application scientists tend to choose software design because they are already very mature, with a large number of abstract and convenient classifications to improve programmer productivity. These trends have made the FPGA field now favoring highly abstract design tools.
FPGA deep learning research milestones: 1987VHDL becomes IEEE standard
1992GANGLION became the first FPGA neural network hardware implementation project (Cox et al.)
1994 Synopsys introduces the first generation of FPGA behavior integration program
1996VIP became the first FPGA implementation of FPGA (ClouTIer et al.)
2005 FPGA market value is close to 2 billion US dollars
2006 First use BP algorithm to achieve 5 GOPS processing capability on FPGA
2011 Altera introduces OpenCL and supports FPGA
Large-scale FPGA-based CNN algorithm research (Farabet et al.)
2016 based on the Microsoft Catapult project, the emergence of FPGA-based data center CNN algorithm acceleration (Ovtcharov et al.)
4. Future Prospects <br> The future of deep learning, whether in terms of FPGA or overall, depends primarily on scalability. For these technologies to successfully solve future problems, they must be extended to support the rapid growth of data scale and architecture. FPGA technology is adapting to this trend, and hardware is moving toward larger memory, smaller feature points, and better interconnectivity to accommodate multiple FPGA configurations. Intel's acquisition of Altera, IBM and Xilinx, both indicate changes in the FPGA field, and may soon see the integration of FPGAs with personal applications and data center applications. In addition, algorithm design tools may move toward further abstraction and experiencing software, attracting a wider range of users.
4.1. Common Deep Learning Software Tools <br> Among the most commonly used software tools for deep learning, some tools have already recognized the need to support OpenCL while supporting CUDA. This will make it easier for FPGAs to achieve deep learning. Although as far as we know, there are currently no deep learning tools that explicitly support FPGAs, but the following table lists which tools are moving toward supporting OpenCL:
Caffe, developed by the Berkeley Center for Visual and Learning, provides informal support for OpenCL in its GreenTea project. Caffe also supports AMD versions of OpenCL.
Torch, a scientific computing framework based on the Lua language, has a wide range of uses, and its project CLTorch provides informal support for OpenCL.
Theano, developed by the University of Montreal, is currently providing gpuarray backends to provide informal support for OpenCL.
DeepCL, an OpenCL library developed by Hugh Perkins, is used to train convolutional neural networks.
For those who have just entered the field and want to choose tools, our advice is to start with Caffe, because it is very common, support is good, and the user interface is simple. It is also easy to experiment with pre-trained models using Caffe's model zoo library.
4.2. Adding Training Freedoms <br> Some people may think that the process of training machine learning algorithms is completely automatic. In fact, some hyperparameters need to be adjusted. This is especially true for deep learning, where the complexity of the model is often accompanied by a large number of possible hyperparameter combinations. The hyperparameters that can be adjusted include the number of training iterations, the learning rate, the batch gradient size, the number of hidden cells, and the number of layers. Adjusting these parameters is equivalent to picking the model that best fits a problem among all possible models. In the traditional approach, the setting of hyperparameters is either empirical or based on a systematic grid search or a more efficient random search. Recently, researchers have turned to adaptive methods, and the results of the hyperparameter adjustment are the basis for configuration. Among them, Bayesian optimization is the most commonly used method.
Regardless of the method used to adjust the hyperparameters, the current training process using fixed architectures limits the possibilities of the model to some extent, that is, we may only look at a part of all the solutions. Fixed architecture makes it easy to explore hyperparameter settings within a model (eg, hidden cell count, number of layers, etc.), but it is difficult to explore parameter settings between different models (eg, different model categories) because It can take a long time to train on a model that does not simply fit a fixed architecture. Conversely, the FPGA's flexible architecture may be better suited to the above optimization types because FPGAs can write a completely different hardware architecture and accelerate at runtime.
4.3. Low power compute clusters Low-energy computing node clusters <br> The most fascinating aspect of the deep learning model is its ability to scale. Whether it's to find complex high-level features from data or to improve performance for data center applications, deep learning techniques often scale across multi-node computing infrastructure. The current solution uses GPU clusters and MPIs with Infiniband interconnect technology to enable parallel computing power and fast data transfer between nodes. However, when the load of large-scale applications is getting different, using FPGAs may be a better method. The FPGA's programmable circuitry allows the system to be reconfigured based on application and load, while the FPGA's power consumption ratio is high, helping next-generation data centers reduce costs.
24V Frequency Transformer,110V 60Hz To 220V 50Hz Transformer,Oil-Filled Electric Transformer, electronic oiled transformer
IHUA INDUSTRIES CO.,LTD. , https://www.ihua-coil.com