Introduction: Reinforcement learning is an area of ​​machine learning that emphasizes how to act based on the environment in order to maximize the expected benefits.

David Silver joined Google DeepMind in 2013, is the lead programmer for the AlphaGo project in the group, and is a lecturer at University College London.
Background
Inspired by reinforcement learning (Reinforcement learning) derives from behaviorism theory in psychology, that is, how organisms, under the stimulation of environmental rewards or punishments, gradually form expectations for stimuli and generate habitual behaviors that can maximize their benefits. This method is universal, so it has been studied in many other fields, such as game theory, cybernetics, operations research, information theory, simulation optimization methods, multi-agent system learning, population intelligence, statistics, and genetic algorithms.
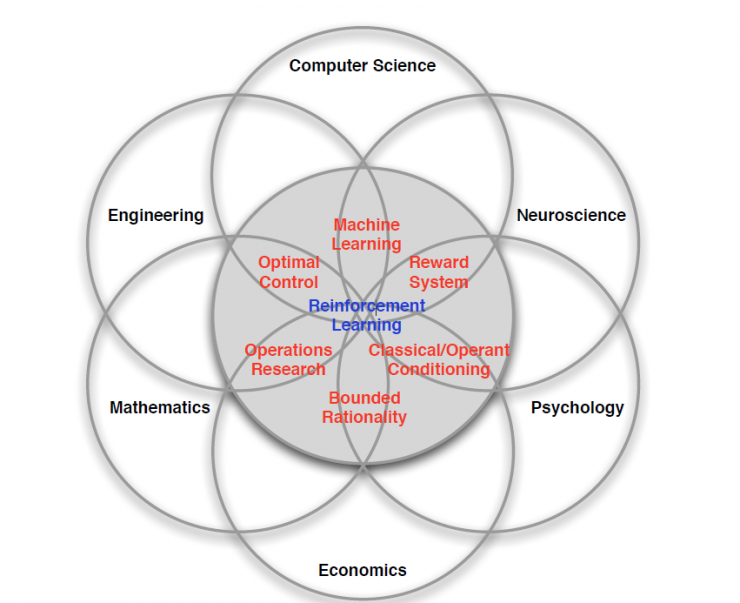
Reinforcement learning is also a product of multidisciplinary and multidisciplinary cross-cutting. Its essence is to solve the "decision making" problem , that is, learn to make decisions automatically. It is different in various fields:
Embodies machine learning algorithms in computer science;
The field of engineering is reflected in determining the sequence of actions to get the best results;
In the field of Neuroscience, it is to understand how the human brain makes decisions. The main research is the reward system.
In the field of psychology (Psychology), research on how animals make decisions and what causes animal behaviors;
The field of economics is reflected in the study of game theory.
All of these problems ultimately boil down to a question of why people can make optimal decisions and how humans do it.
Principle
Reinforcement learning is a Sequential Decision Making problem. It requires continuous selection of behaviors, from which the maximum return is the best result. It does this by first attempting to do something without any label telling the algorithm what to do - and then get a result and feedback on the previous behavior by judging whether the result is right or wrong . This feedback can be used to adjust the previous behavior. By constantly adjusting the algorithm, one can learn under what circumstances to choose what kind of behavior to get the best result.
There are many differences between reinforcement learning and supervised learning. It can be seen from the foregoing that supervised learning has a label that tells the algorithm what kind of input corresponds to what kind of output. Reinforcement learning does not have a label to tell it what kind of behavior it should perform under certain circumstances. Only a reward signal that ultimately returns after a series of behaviors can be used to judge whether the current choice is good or bad. In addition , the result feedback of reinforcement learning is delayed . Sometimes it may take a lot of steps to know whether the choice of a certain step is good or bad, and supervised learning will feedback to the algorithm immediately if it makes a bad choice. The input to reinforcement learning is always changing, unlike supervised learning—inputs are distributed independently. Whenever an algorithm makes a behavior, it affects the input of the next decision. The difference between reinforcement learning and standard supervised learning is that it does not require correct input/output pairs, nor does it require precise correction of suboptimal behavior. Reinforcement learning is more focused on online planning and requires a balance between Exploration (exploration of the unknown) and Exploitation (use of existing knowledge).
| Implementation process
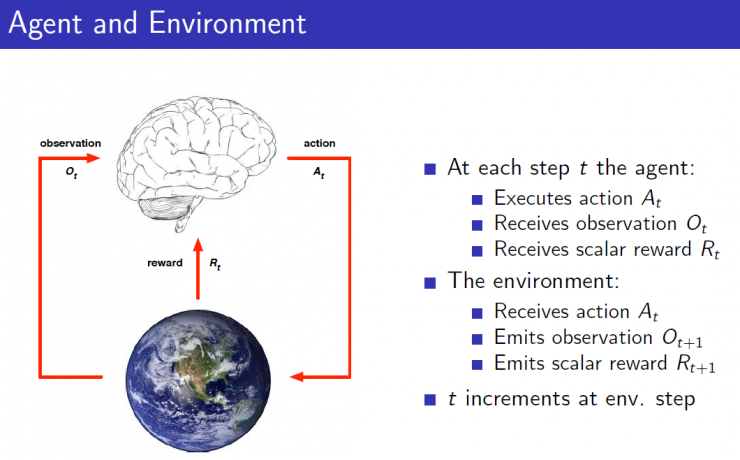
Reinforcement learning decision-making process requires the establishment of an agent (brain section in the figure), and the agent can perform an action (such as determining where the chess piece is, and what the next step of the robot is). The Agent can receive an observation of the current environment, for example, the current robot's camera captures a scene. The agent can also receive rewards after it performs an action, that is, in the tth step, the workflow of the agent is to perform an action At, obtain the environment observation status Ot after the action, and obtain feedback reward Rt for this action. The environment environment is the object that the agent interacts with. It is an object whose behavior is uncontrollable. The agent does not know what kind of reaction the environment will make to different actions. The environment will tell the current environment state of the agent through the observation while the environment It is possible to give the agent a reward based on possible final results. For example, Go is an environment. It can estimate the proportion of black and white winning or losing according to the current state of the game. Thus in step t, the workflow of the environment is to receive an At, respond to this action and then pass the environment status and evaluate the reward to the agent. Reward reward Rt is a feedback scalar value, which indicates how good or how bad the decision made by the agent in the tth step is, and the goal of the entire reinforcement learning optimization is to maximize the cumulative reward.
The composition of Agent in reinforcement learning

An agent consists of three parts: Policy, Value function, and Model. However, these three parts do not have to exist at the same time.
Policy : It determines the action based on the currently observed observation, which is a mapping from state to action. There are two forms of expression. One is the Deterministic policy, ie, a=π(s)a=π(s). In some state s, certain action a will be performed. One is the Stochastic policy (random strategy) ie π(a|s)=p[At=a|St=s]π(a|s)=p[At=a|St=s], which is in some form The probability of executing an action in the state.
Value function : It predicts the expected future rewards in the current state. VÏ€(s)=EÏ€[Rt+1+rRt+2+...|St=s]VÏ€(s)=EÏ€[Rt+1+rRt+2+... |St=s]. Used to measure the current state of good or bad.
Model : Predict what changes the environment will make next to predict what the agent receives or rewards. There are two types of models, one is the transition model that predicts the next state, that is, Pass'=p[St+1=s'|St=s,At=a]Pss'a=p[St+1=s '|St=s,At=a], one is the reward model that predicts the next reward, namely Ras=E[Rt+1|St=s,At=a]Rsa=E[Rt+1|St=s, At=a]
Explore and use
Reinforcement learning is a trial-and-error way of learning: at the very beginning it is not clear how the environment works, it is unclear what kind of action is performed, and what kind of action it is. (behavior) is wrong. Therefore, the agent needs to find a good policy from the constant trial experience, so as to obtain more rewards in the process.
In the learning process, there will be a trade-off between Exploration and Exploitation.
Exploration will give up some known reward information and try some new ones - that is, under certain conditions, the algorithm may have learned which action to choose to make reward bigger, but it cannot be done every time. The same choice, perhaps another option that has not been tried will make reward greater, that is, Exploration hopes to be able to explore more information about the environment.
Exploitation means maximizing reward based on known information.
For example, when both choose a restaurant - Exploration will choose your favorite restaurant, and Exploitation will try to choose a new one.
Summary : After the introduction of the background, principles, implementation process and related concepts of reinforcement learning in the article, I believe that everyone will have a basic understanding of reinforcement learning. Follow-up implementation process and detailed value function, strategy approach, please continue to pay attention to our next article.
PS : This article was compiled by Lei Feng Network (search "Lei Feng Network" public number attention) , refused to reprint without permission!
Via David Silver
ZGAR TWISTER Disposable
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

ZGAR TWISTER Vape,ZGAR TWISTER Vape disposable electronic cigarette,ZGAR TWISTER Vape pen atomizer ,ZGAR TWISTER Vape E-cig,TWISTER Vape disposable electronic cigarette
Zgar International (M) SDN BHD , https://www.zgarvape.com