The Web is an open platform, which has also laid the foundation for the booming development of the Web from the early 1990s until today. However, the so-called Cheng Xiao Xiao and Xiao He, the open special type, search engine and easy-to-learn HTML and CSS technology make the Web become the most popular and mature information communication medium in the Internet field; but nowadays as commercial software, Web The copyright of the content information on this platform is not guaranteed, because the content of your web page can be obtained by some crawling programs realized by low cost and low technical thresholds compared with the software client. This is the topic that this series of articles will explore - web crawlers.
There are many people who believe that the Web should always follow an open spirit, and the information presented on the page should be shared unreservedly to the entire Internet. However, I believe that in the IT industry to the present day, the Web is no longer the so-called "hypertext" information carrier that competed with PDF. It has been the ideology of a lightweight client software. Existed. With the development of commercial software to this day, the Web has to face the problem of intellectual property protection. Imagine that if the original high-quality content is not protected, plagiarism and piracy are rampant in the online world, which is actually unfavorable to the benign development of the Web ecosystem. It is also difficult to encourage the production of more quality original content.
Unauthorized crawler crawling programs are a major threat to the web's original content ecosystem. Therefore, to protect the content of the website, you must first consider how to crawl the crawler.
From the point of view of the reptile's offense and defenseThe simplest crawler is the http request supported by almost all server and client programming languages. Just send an http get request to the url of the target page to get the full html document when the browser loads the page. We call this "synchronization page."
As a defensive party, the server can check whether the client is a legitimate browser program or a script-based crawler according to the User-Agent in the http request header, thereby determining whether the real page information content is to be I will send it to you.
This is of course the smallest pediatric defense. The reptile as an offensive party can completely falsify the User-Agent field. Even if you want, the http header get method, the request header's Referrer, the cookie, etc. all the crawlers can be easily used. Forged.
At this point, the server can use the browser http header fingerprint to identify whether each field in your http header matches the characteristics of the browser according to your own browser vendor and version (from User-Agent). The compliance is treated as a crawler. This technology has a typical application, that is, in the PhantomJS1.x version, because the underlying call of the Qt framework network library, there are obvious Qt framework network request features in the http header, which can be directly identified and intercepted by the server.
In addition, there is a more perverted server-side crawler detection mechanism, which is to make http requests for all access pages, plant a cookie token in http response, and then go to some ajax interfaces that are executed asynchronously in this page. Check if the request contains a cookie token, and return the token back to indicate that it is a legitimate browser visit. Otherwise, the user who has just issued the token accesses the page html but does not access the ajax that is called after executing js in the html. The request is most likely a crawler.
If you don't carry a token directly to access an interface, this means that you have not requested an html page to directly initiate a network request to an interface that should be accessed by ajax within the page, which clearly proves that you are a suspicious crawler. The well-known e-commerce website amazon is the defensive strategy adopted.
The above is based on the server-side verification crawler program, some of the routines that can be played.
Based on client js runtime detectionModern browsers give JavaScript the power, so we can make all the core content of the page into js asynchronous request ajax to get the data and render it on the page, which obviously raises the threshold for crawling content. In this way, we transfer the confrontation battlefield between crawling and anti-crawling from the server to the js runtime in the client browser. Let's talk about the crawler crawling technology combined with the client js runtime.
The various server-side verifications just mentioned have certain technical thresholds for ordinary python and http-fetching programs written in Java. After all, a web application is black-box for unauthorized crawlers. A lot of things need to be tried a little bit, and it takes a lot of manpower and resources to develop a good crawling program. As long as the web site as a defensive party can easily adjust some strategies, the attacker needs to spend the same time again to modify the crawler crawling logic. .
At this point you need to use the headless browser. What is this technology? In fact, it is said that the program can operate the browser to access the web page, so that the person writing the crawler can expose the api of the program call to realize the complex grab business logic by calling the browser.
In fact, this is not a new technology in recent years. There used to be PhantomJS based on webkit kernel, SlimerJS based on Firefox browser kernel, and even trifleJS based on IE kernel. Interested to see here and here are two headless browsers. Collect the list.
The principle of these headless browser programs is to transform and package some open source browser C++ code to implement a simple browser program without GUI interface rendering. But the common problem with these projects is that because their code is based on the trunk code of a version of the kernel such as fork official webkit, it is impossible to follow up some of the latest css properties and js syntax, and there are some compatibility issues, not as real. The release version of the GUI browser.
The most mature and most used one should be PhantonJS. I have written a blog about the identification of this crawler, which will not be repeated here. PhantomJS has many problems, because it is a single-process model, there is no necessary sandbox protection, and the browser kernel is less secure.
Now the Google Chrome team has opened the headless mode api in the chrome 59 release and open sourced a headless chromium dirver library based on Node.js calls. I also contributed a deployment dependency list for the centos environment for this library.
Headless chrome is a unique killer in the headless browser. Because it is a chrome browser, it supports various new css rendering features and js runtime syntax.
Based on this approach, the crawler as an offensive party can bypass almost all server-side validation logic, but these crawlers still have some flaws in the client's js runtime, such as:
Check based on plugin object
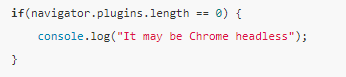
Language-based inspection
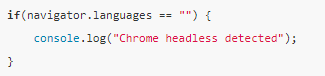
Webgl based check

Based on browser hairline features check
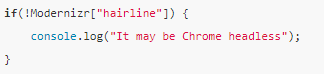
Check for img objects generated based on the error img src attribute

Based on the judgment of some of the above browser features, it is basically possible to kill most of the headless browser programs on the market. At this point, the threshold for web crawling is actually increased. Developers who require scripting programs have to modify the C++ code of the browser kernel, recompile a browser, and the above features are for the browser kernel. The changes are not small.
Furthermore, we can also check the properties and methods of the js runtime, DOM and BOM native objects based on the browser brand and version model information described in the UserAgent field of the browser, and observe whether the features conform to the version of the browser. The characteristics that the device should have.
This method is called browser fingerprint checking technology, and relies on the collection of api information of various types of browsers by large web stations. As an offensive side of writing a crawler, you can pre-inject some js logic into the headless browser runtime to fake the characteristics of the browser.
In addition, when we researched the browser side using the js api for robots browser detect, we found an interesting little trick. You can disguise a pre-injected js function as a native function and take a look at the following code:

The reptile attacker may pre-inject some js methods, wrapping some of the native apis with a proxy function as a hook, and then using this fake js api to overwrite the native api. If the defender checks the judgment on this basis based on the check of the [native code] after the function toString, it will be bypassed. So a stricter check is needed, because the bind(null) forgery method does not have a function name after toString.
Anti-reptile silver bulletThe current anti-crawling, robotic inspection means, the most reliable is the verification code technology. However, the verification code does not mean that the user must be forced to enter a series of alphanumeric characters. There are also many behavior verification techniques based on the user's mouse, touch screen (mobile) and other behaviors. The most mature one is Google reCAPTCHA.
Based on the above identification techniques for users and reptiles, the defensive party of the website ultimately needs to ban the ip address or apply a high-strength verification code strategy to the ip's visiting users. In this way, the attacking party has to purchase the ip proxy pool to crawl the content of the website information, otherwise the single ip address can easily be blocked and cannot be crawled. The threshold for crawling and anti-crawling has been raised to the level of the economic cost of the ip proxy pool.
Robot protocolIn addition, there is a “white way†in the field of crawler crawling technology called robots protocol. You can access /robots.txt in the root directory of a website. For example, let's take a look at the robot protocol of github. Allow and Disallow declare the authorization to grab each UA crawler.
However, this is only a gentleman's agreement. Although it has legal benefits, it can only limit the spiders of commercial search engines. You can't limit those "climbing fans".
Written at the end
The crawling and counter-attacking of the content of the webpage is destined to be a cat and mouse game with a height of one foot. You can never completely block the way of the crawler program with a certain technology. All you can do is to improve the attack. The cost of crawling, and the more accurate grasp of unauthorized crawling behavior.
Bohr Optics Co.,Ltd has been a global leader in the production and distribution of scientific optical components for over 10 years.
We supply optical components to some of the leading companies within scientific, defence, medical, pharmaceutical, opto-electronics industries around the globe, BohrmOptics is situated in Chang Chun of China,for convenient distribution to all over the world.
Our highly qualified and experienced workforce enables us to offer custom made solutions economically, in virtually any shape and size. Combining traditional methods with modern state-of-the-art systems and metrology equipment enables us to offer quality, competitiveness and prompt delivery schedules within 2 - 3 weeks from receipt of order.
Free technical advice is always available from our knowledgeable technical team.
All optics are quality checked using state-of-the-art metrology equipment.
Bohr Optics company supply bespoke precision optical components to your custom specification and we also hold a large stock of over 10000 standard components available to purchase on-line for prompt delivery to your door
We are able to manufacture and supply optical components and coatings to both international and China quality standards,wish we can cooperate in the future.
Optical spherical lens,UV filter,IR filter,Optical window,Metal mirror
Bohr Optics Co.,Ltd , https://www.bohr-optics.com